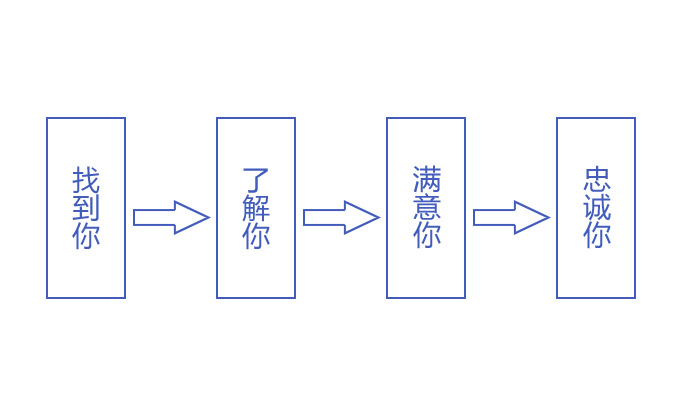
笔者曾认真研究和分析过产品从企业到消费者手中的路径,得出一个结论,消费者向企业购买产品共经历了以下四个步骤:找到你、了解你、满意你、忠诚你。企业在建立好网站之后,首先就是要让客户找到你。很显然,要想让客户找到你,那么网站就必须被搜索引擎收录,能在搜索引擎的搜索结果页面上查找到。因此“网站收录”是企业网站进行网络营销的当务之急,如下图所示:
产品从企业到消费者手中共经历的四个步骤
不同的搜索引擎对网站收录情况不一样,但基本收录功能是差不多的,下面以百度收录为例介绍搜索引擎收录网站的原理。
网络蜘蛛的基本原理:
要想了解网站收录,首先要了解网络蜘蛛的基本工作原理。网络蜘蛛又称为网络机器人,英文名字叫Web Spider,这是一个非常形象的名字,如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,找到在网页中其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到把这个网站所有的网页都抓取完。
笔者更愿意把网络蜘蛛称为抓取机器人,这是因为网络蜘蛛在抓取所有的页面文件之后,会把抓取到的文件存入数据库,可以把这个数据库比作为一个非常庞大的Excel表格,这个Excel表格的每一行就代表一个网页,而网页的文字则被分解到每个单元格里。
当用户在搜索引擎界面中输入关键词时,搜索引擎程序就会对撞索词进行处理,从搜索引擎数据库找到所有包含搜索词的页面,并根据排名算法计算出各个网页的排名。对于这个“搜索词处理”的环节,就好像在一个庞大的虚拟的Excel表格进行“条件筛选”的过程,当然整个搜索引擎的过程比这复杂得多。
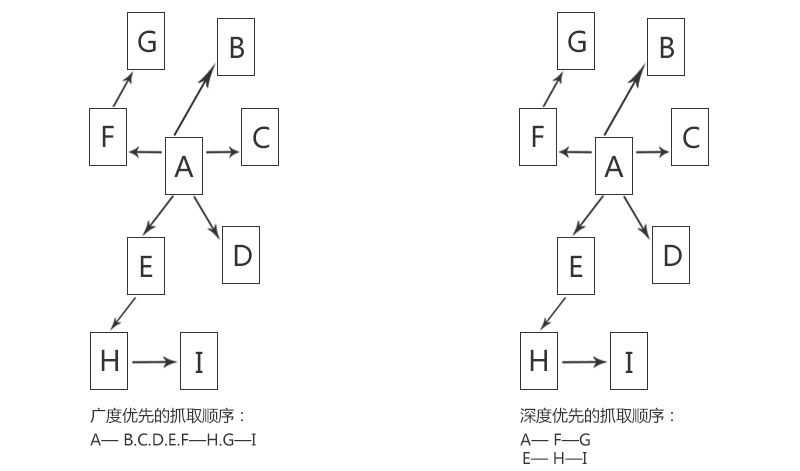
网络蜘蛛在抓取网页时,一般有两种策略:广度优先和深度优先,如下图所示。
网络蜘蛛抓取网页策略
(1)广度优先
广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。
(2)深度优先
深度优先是指网络蜘蛛会从起始页开始,一个链接一个链接地跟踪下去,处理完这条线路之后再转人下一个起始页,继续跟踪链接。这个方法有一个优点就是网络蜘蛛在抓取的时候比较容易。
每个网络蜘蛛都有自己的名字,在抓取网页时,都会向网站表明自己的身份。例如Google网络蜘蛛称为GoogleBot,百度网络蜘蛛称为BaiDuSpider,雅虎网络蜘蛛称为Inktomi Slurp等。
本文链接:http://www.wlxin.com/xinwenzhongxin/562.html
|