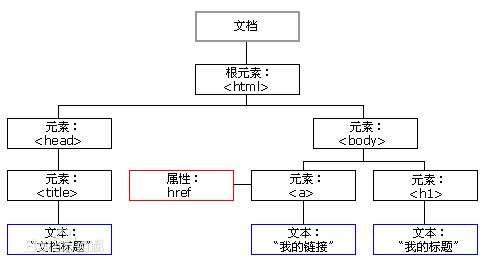
DOM是什么?跟东莞网站建设的关联
DOM既能够用于处置HTML也能够用于处置XML并且DOM有多个版本,分别为level1level2和level3文档对象模型(DocumentObjectModel简称DOMW3C组织引荐的处置可扩展标志言语的规范编程接口。 东莞网站建设上,组织页面(或文档)对象被组织在一个树形构造中,用来表示文档中对象的规范模型就称为DOMDocumentObjectModel历史能够追溯至1990年代后期微软与Netscap阅读器大战”双方为了JavaScript与JScript一决生死,于是大范围的赋予阅读器强大的功用。微软在网页技术上参加了不少专属事物,既有VBScriptActiveX以及微软自家的DHTML格式等,使不少网页运用非微软平台及阅读器无法正常显现。DOM即是当时蕴酿出来的杰作。每个版本都是对前一版本的进步,最早的leve1仅包含DOMHTML和DOMCoreDOMLevel2规范簇包含如下6个标准。
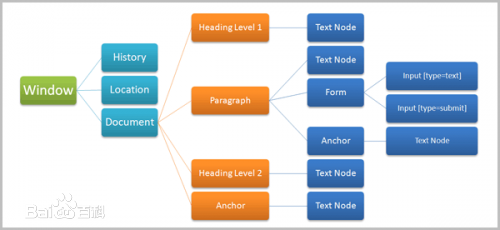
1.DocumentObjectModelLevel2Core
2.DocumentObjectModelLevel2Views
3.DocumentObjectModelLevel2Events
4.DocumentObjectModelLevel2Style
5.DocumentObjectModelLevel2TranversandRange
6.DocumentObjectModelLevel2HTML
目前大局部阅读器软件都能够局部获取全部的完成DOMLevel2规范簇,HTML5DOMAPI也都是大量基于DOMLevel2规范簇的这也是本书为何引见DOMLevel2缘由。
当一个HTML网页被加载到阅读器中时,阅读器会首先解析这个网页文档,会将网页解析为文档对象模型。
优点和缺陷编辑
DOM优势主要表如今:易用性强,运用DOM时,将把一切的XML文档信息都存于内存中,并且遍历简单,支持XPath加强了易用性。
DOM缺陷主要表如今:效率低,解析速度慢,内存占用量过高,关于大文件来说简直不可能运用。另外效率低还表如今大量的耗费时间,由于运用DOM停止解析时,将为文档的每个elementattributprocessing-instruct和comment都创立一个对象,这样在 DOM机制中所运用的大量对象的创立和销毁无疑会影响其效率。
文档对象模型是文档在内在中的表示方式,一个应用顺序接口,定义了这文档的逻辑构造,以及一套访问和处置文档的方法,例如,客户端阅读器是一个处置HTML和XML文档的应用顺序,必需将HTML或XML文档解析成DOM才可以以编程方式读取操作和呈现HTML或XML文档。
本文链接:http://www.wlxin.com/xinwenzhongxin/395.html
|